其实群晖的SSD Cache蛮鸡肋的,单条SSD只能做只读Cache,一个SSD Cache只能加速一个存储池等。
从《群晖的磁盘管理初探》可以知道,DSM的RAID就是标准的Linux Raid,使用mdadm软件来操作,而存储池与空间则是基于LVM搭建出来。那么现在DSM的SSD Cache功能则是基于Linux的flashcache来实现,并用于LVM中的lv(即存储空间)。 即:mdadm管理RAID阵列,lvm2管理分区,flashcache管理SSD缓存加速。
如果想要把Nvme的两个盘位用于加速系统分区,以及把这两个盘新组成的第三数据分区用于存储数据分区的话,可以参考资料中的第一、三篇文章去处理。
dm-cache
又叫 Device Mapper Cache。dm-cache是设备映射器目标,首先提交到kernel-3.9。它使用针对基于闪存的SSD进行优化的I / O调度和缓存管理技术。设备映射程序目标(dmcache)重新使用精简资源调配库中使用的元数据库。write-back和writethrough都由dm-cache支持,write-back是默认模式。
由dm-cache创建的虚拟缓存设备使用源设备(Origin device)、缓存设备(Cache device)和元数据设备(Metadata dev)这三个物理设备来构建。结构如下图所示:
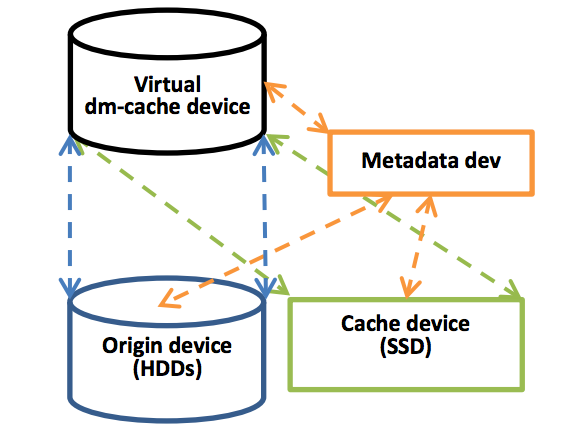
源设备是实际(较慢)目的存储设备。
高速缓存设备是用于临时存储用户数据的较快设备。
元数据设备记录块布局,它们的dirty flags和其他内部数据所需的策略。
DSM的实现
DSM封装了一个命令行工具叫flashcache,当创建SSD Cache的时候,可以在/var/log/space_operation.log中看到,执行了一堆与flashcache有关的操作。如:
# 以下是一个SSD Cache创建的完整过程
/sbin/sfdisk --fast-delete -1 /dev/sdd
/sbin/sfdisk -M1 /dev/sdd
/sbin/sfdisk -N1 -uS -q -f -j2048 -z-1 -tfd -F /dev/sdd
/sbin/mdadm -C /dev/md4 -e 1.2 -amd --assume-clean -R -l1 -f -n1 -x0 /dev/sdd1
/bin/dd if=/dev/zero of=/dev/md4 bs=512 count=1 status=none
/sbin/pvcreate -ff -y --metadatasize 512K /dev/md4
/sbin/vgcreate --physicalextentsize 4m /dev/shared_cache_vg1 /dev/md4
/sbin/lvcreate /dev/shared_cache_vg1 -n syno_vg_reserved_area --size 12M
/sbin/lvcreate /dev/shared_cache_vg1 -n alloc_cache_1 --size 14336M
/usr/bin/flashcache_destroy -f /dev/shared_cache_vg1/alloc_cache_1
/usr/bin/flashcache_enable -s 14680064k -p around cachedev_0 /dev/shared_cache_vg1/alloc_cache_1 /dev/vg2/volume_2 -n 12 -g fWxxpB-gsvd-uDCl-1HNT-bBcC-BVJv-dIsVgO
/usr/bin/flashcache_create -n 12 -s 14680064k -p around -g fWxxpB-gsvd-uDCl-1HNT-bBcC-BVJv-dIsVgO cachedev_0 /dev/shared_cache_vg1/alloc_cache_1 /dev/vg2/volume_2 从硬盘操作日志来看,那个/dev/shared_cache_vg1/alloc_cache_1就是所创建的Cache设备,也是一个Raid+Lvm设备,然后使用flashcache挂载到/dev/vg2/volume2存储池来使用。创建完成之后,会形成以下的配置文件,以后直接load就可以,并且会存在以下的进程进行维护
进程:
/usr/syno/sbin/synocachepinfiled --config-path /usr/syno/etc/flashcache_pin_file.conf
配置:
:/usr/syno/etc# cat flashcache.conf
[YbJJ2O-qXaO-zUfv-QXH6-GumC-Evkj-IQXTyc]
WriteMode = around
loaded = 1
SSDDevPath = /dev/shared_cache_vg1/alloc_cache_1
DirtyThreshPercent = 0
SpaceMissing = 0
SkipSeqIO = 1
MaxDegradeFlush = 0
FlushState = normal
SSDUUID = nYIQAc-Ij0S-TdAg-ygmN-NkeX-jRki-cfpGof
SpacePath = /dev/vg2/volume_2
SSDID = alloc_cache_2_1
DiskLoc = 0-4
CacheMissing = 0
ReclaimPolicy = lru
CreateCritSection = 0
ReferencePath = /volume2
CacheVersion = 3
ConfigSource = 7
CacheSizeByte = 15032385536
DelaySeconds = 0
ApmFlushDone = 0DSM的SSD Cache
在这里我使用一张16G的Sata SSD来演示DSM系统是如何使用SSD当缓存的
# fdisk /dev/sdd 再输入p,列出硬盘分区,整个硬盘都分一个区,用于SSD Cache
Device Boot Start End Sectors Size Id Type
/dev/sdd1 2048 31262489 31260442 14.9G fd Linux raid autodetect
# cat /proc/mdstat 这个sdd1分区用于md4设备,这是标准的Linux Raid设备
Personalities : [raid1]
md4 : active raid1 sdd1[0]
15629184 blocks super 1.2 [1/1] [U]
# pvs md4用于LVM pv设备,并用于承载shared_cache_vg1这个VG的数据
PV VG Fmt Attr PSize PFree
/dev/md4 shared_cache_vg1 lvm2 a-- 14.90g 912.00m
# lvs --all --options +devices 有两个LV使用了这个VG组,其中的alloc_cache_1是当前创建的主要的SSD Cache分区
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices
alloc_cache_1 shared_cache_vg1 -wi-ao---- 14.00g /dev/md4(3)
syno_vg_reserved_area shared_cache_vg1 -wi-a----- 12.00m /dev/md4(0)
# dmsetup table cachedev_0 查看确定dm设备的dm表,这里可以看到dm-cache在哪个区
0 3896508416 flashcache-syno conf:
ssd dev (/dev/shared_cache_vg1/alloc_cache_1), disk dev (/dev/vg2/volume_2) cache mode(WRITE_AROUND)
capacity(14336M), associativity(512), data block size(64K)
skip sequential thresh(1024K)
total blocks(229376), cached blocks(19179), cache percent(8)
nr_queued(0)
split-io(0) support pin file(0) version(12)
....
# dmsetup status 列出dm设备的状态
cachedev_0: 0 3896508416 flashcache-syno stats: 被缓存的dm分区
reads(193914), writes(23435)
read hits(6821), read hit percent(3) 缓存命中率
replacement(0), write replacement(0)
invalidates(3)
pending enqueues(530), pending inval(0)
no room(0)
disk reads(187093), disk writes(23435) ssd reads(6291) ssd writes(19296)
uncached reads(167797), uncached writes(23435), uncached IO requeue(0)
disk read errors(0), disk write errors(0) ssd read errors(0) ssd write errors(0)
uncached sequential reads(167789), uncached sequential writes(3840)
pid_adds(0), pid_dels(0), pid_drops(0) pid_expiry(0)
write miss ssd(0)
dirty writeback kb(0), dirty writeback sync kb(0)
......
dmcg rebalance cnt(0) dmcg num io(0) dmcg io pending(0)
shared_cache_vg1-alloc_cache_1: 0 29360128 linear
shared_cache_vg1-syno_vg_reserved_area: 0 24576 linear 迁移数据到更快的固态硬盘
为了达到更好的性能,我们还应该把一些常用的对IO性能敏感的东西迁移到NVME上,包括但不限于:
- 系统的PostgreSQL/Mariadb数据库,通常位于
/volume1/@database,但也可能分布在多块盘上 - 自己安装的Mariadb10数据库,位于
/var/packages/MariaDB10,更细的数据位于/volume1/@appdata/MariaDB10和/volume1/@appstore/MariaDB10 - 软件包,通常位于
/volume1/@appstore,但也可能分布在多块盘上 - CloudSync的SQLite数据库,通常位于
/volume1/@cloudsync - Docker的镜像和容量数据,通常位于
/volume1/@docker - VMM的虚拟磁盘文件,通常位于
/volume1/@Repository
迁移的方法很简单,先rsync,然后再mount –bind,比如:
sudo rsync -a /volume1/\@appstore/ /volume1/homes/admin/nvme/\@appstore/
sudo mount --bind /volume1/homes/admin/nvme/\@appstore /volume1/\@appstore理想情况下,应该先把相关服务停止后(用synoservice命令可以启停服务)再迁移数据,避免迁移过程中有新数据写入造成不一致。为了保证万无一失,建议可以写个迁移脚本,在系统启动过程中所有服务还没有启动前运行一下这个脚本。
这一步是有风险的,因为万一未来某一次mount –bind没有成功或者没有做mount –bind,系统就无法访问到正确的数据了,这对于系统数据库之类的,还是有一定影响的,会造成数据不一致。
那么可以让这些操作重启自动生效
写一个脚本,用于在未来重启时重建RAID和mount相关目录,比如:
# 先把NVME上的数据盘mount起来
mount /dev/nvme0n1p3 /volume1/homes/admin/nvme
# 把SWAP的RAID 1扩容,并把NVME上的分区加进去
# 系统分区不需要,因为会自动完成。
# 但SWAP的RAID每次重启都会重建,所以每次都需要扩容。
mdadm --grow --raid-devices=5 /dev/md1
mdadm --manage /dev/md1 --add /dev/nvme0n1p2
# 把相关的目录mount --bind上去
mount --bind /volume4/homes/admin/nvme/\@appstore /volume4/\@appstore
mount --bind /volume4/homes/admin/nvme/\@cloudsync /volume4/\@cloudsync
mount --bind /volume4/homes/admin/nvme/\@database /volume4/\@database
mount --bind /volume4/homes/admin/nvme/\@docker /volume4/\@docker
mount --bind /volume4/homes/admin/nvme/\@Repository /volume4/\@Repository
# 重新设置RAID writemostly策略
echo writemostly > /sys/block/md0/md/dev-sda1/state
echo writemostly > /sys/block/md0/md/dev-sdb1/state
echo writemostly > /sys/block/md0/md/dev-sdc1/state
echo writemostly > /sys/block/md1/md/dev-sda2/state
echo writemostly > /sys/block/md1/md/dev-sdb2/state
echo writemostly > /sys/block/md1/md/dev-sdc2/state修改/etc/rc,在SYNOINSTActionPostVolume这一行后面,增加一行对上述脚本的调用。SYNOINSTActionPostVolume执行完后,刚好是所有磁盘都mount好但是没有任何服务启动的时刻,所以这时做mount –bind是最合适的。如果你第三步数据迁移想在重启时做,也是加在这个位置。
这一步是比较不完美的,因为需要修改系统文件,而系统文件有可能会在更新DSM时被覆盖回去,万一被覆盖回去,系统启动后就是一个没有mount –bind的状态了,即使那时再改一遍脚本再重启,DB的一致性可能已经无法保证了。我暂时选用了一个带有一点防御性的做法(同样不是万无一失的):在更新DSM前,把/usr/sbin/reboot改名,这样更新完DSM后系统不会被自动重启,我就可以有机会检查/etc/rc有没有覆盖,如果被覆盖,可以自己改回来以后再重启系统。
其它经验和坑
- 数据迁移必须用mount –bind,不能用软链,已知有些应用组件在软链的情况下不能正常工作
- /volume1/@tmp不能迁移到NVME,即使用mount –bind,也会造成Drive等组件不能正常工作
- 现在的做法,NVME的第二个分区是后加到SWAP分区的RAID里的,所以每次重启都会有个重新同步的过程,IO会打高一会儿,并且完成后DSM会弹一个提示:一致性检查完成。但总体是可以忍的,所以我就没有去深究用什么方法可以在建立SWAP的RAID时就直接把它一起建进去了,因为我还是想尽可以少侵入DSM系统
- 用户的共享文件夹也可以通过mount –bind迁到NVME上,但是这样做会造成在共享文件夹管理界面上不能正常查看共享文件夹相关信息,所以建议只对共享文件夹里的目录进行mount –bind
- 如果你只有一条NVME,或者有两条但没有做RAID,那么迁移上去的那些系统文件都是单点(虽然原本在磁盘没有RAID的话是单点),需要留意其中的风险