缘起
最近有一项工作需要对Word文档进行编写,大概200多项内容,内容来自一个Word文档需求说明书,输出的结果为好几份文件,分别为概要设计说明书、测试说明书、FPA等文档,格式有特别要求。这一项工作,公司本身有现成的工具基于需求说明书来生成对应的概要设计说明书等一系列的衍生文档,但这一次的数据来源是一个基于旧模板的需求说明书,公司的工具不支持处理。
因此,需求就是使用python读取旧格式需求说明书生成新格式需求说明书,然后新格式需求说明书经过公司文档工具,生成新格式概要设计说明书、测试说明书、FPA等一系列文档。
在这一个过程中,遇到的一系列问题,基本是官方文档所查询不到资料的问题,而且基于python-docx所致pycharm并没能很好地支持智能提示,代码编写过程中遇到了不少困难。这一篇文章记录需求解决所使用的代码与方案。
本文所使用的三方模块为python-docx和python-docx-template,使用python3.8环境,那两个功能模块包的安装命令如下:
pip install python-docx
pip install docxtpl功能需求
基于python-docx读取资料,修改特定的内容,读取模板生成新的资料文件。
就这么一个功能,写完800多行代码,足足写了3天多,中间各种各样的调试。
就因为这个模块资料少,python-docx-template又是基于python-docx、jinja2,资料还是一如既往地少。
python-docx概念
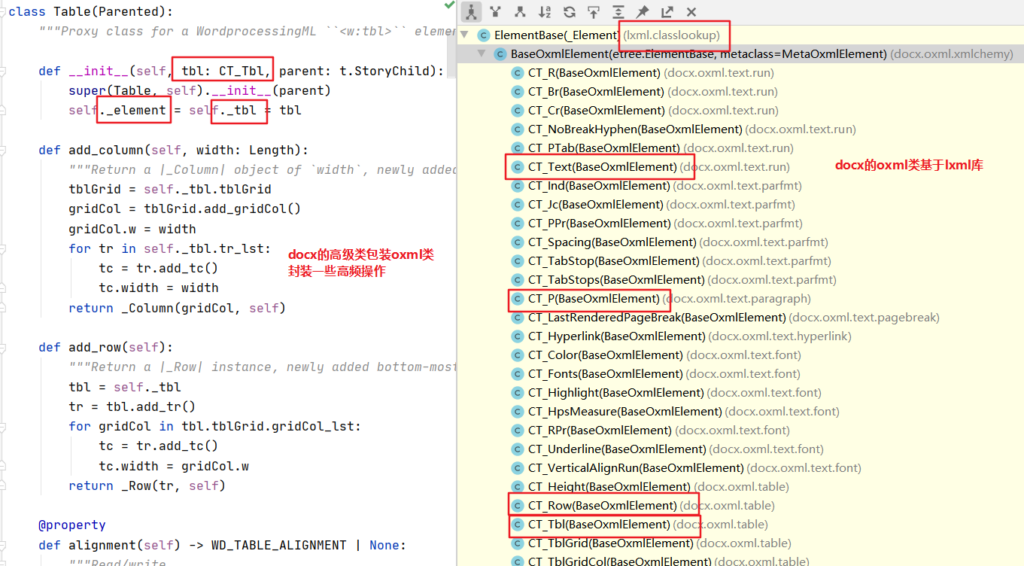
python-docx类包含有Docment、Paragraph、Run、Table、Section等,其中使用得最多的就是前四个类,第5类很少用,这次就没用使用到。
Docment代表一个word文档,Paragraph(段落)、Run(字块)的关系如图

上面几个类,每一个类实例都有内容的_element变量,这个指向CT_xxx类,这些CT_xxx是一些以lxml为基的类,定义了docx中的数据类型,各种底层的操作其实就是操作XML文件。
另外要注意的是,paragraph可以使用str改写text,如:paragraph.text = ‘abc\n\tefg',这是一个包含换行以及第二行前制表符的段落,使用wps或者word打开,看着像两个段落,但其实还是一个段落而不是两个段落,在这里我踩了一个坑,文件使用wps打开,看着没问题,但实际上不是单独的段落,结构不对导致死活过不去工具。
python-docx只支持docx,因此遇到doc文件,需要使用其他工具转换为docx再给python-docx读取,源代码看了之后,会发现其实docx文件,底层就是xml格式的,docx中的x代表着xml,python-docx又是基于lxml的原因就是这个。
官方资料:python-docx、python-docx-template
遍历文档内容
由于我需要的内容只在特定的章节中,文件资料中总共300多个章节。编码一开始,我就直接去python-docx的官方网站阅读资料,查看使用案例,但好巧不巧,python-docx的Docment类没有提供定位功能,只能使用遍历,这次的文档没有图片,只有段落与表格,所以相对来说,结构简单。
遍历段落与表格
def iter_block_items(parent):
"""
https://blog.csdn.net/panjielove/article/details/104914892
Yield each paragraph and table child within *parent*, in document order.
Each returned value is an instance of either Table or Paragraph. *parent*
would most commonly be a reference to a main Document object, but
also works for a _Cell object, which itself can contain paragraphs and tables.
"""
if isinstance(parent, Document):
parent_elm = parent.element.body
elif isinstance(parent, _Cell):
parent_elm = parent._tc
else:
raise ValueError("something's not right")
for child in parent_elm.iterchildren():
# print(child.tag, child, " ", end="")
if isinstance(child, CT_P):
yield Paragraph(child, parent)
elif isinstance(child, CT_Tbl):
yield Table(child, parent)
# table = Table(child, parent)
# for row in table.rows:
# for cell in row.cells:
# for paragraph in cell.paragraphs:
# yield paragraph
if __name__ == '__main__':
dfile = Document(r"2023年数据库国产化适配改造项目(亚信)(第1次)[第1批]_需求规格说明书.docx")
for block in iter_block_items(dfile):
if block.style.name == "Table Grid":
pass
if block.style.name == "Heading 1":
pass读取表格
忽略表格样式,读取表格内容
def read_table_data(tab: Table):
"""
read cell data of table
:param tab:
:return: [{head1: cell1, head2: cell2}]
"""
table_data = []
keys = None
for i, row in enumerate(tab.rows):
text = (cell.text for cell in row.cells)
if i == 0:
keys = tuple(text)
continue
row_data = dict(zip(keys, text))
table_data.append(row_data)
return table_data删除表格行
有一个表格需要删除错误的行数据,使用table.rows定位到某一行之后,使用以下代码删除。
def table_remove_row(table, row):
"""
remove table row with lxml operation
:param table: Table Object
:param row: _Row Object
:return:
"""
tbl = table._tbl
tr = row._tr
tbl.remove(tr)删除段落
从原文档直接读取出Docment之后,在渲染模板之后,写回文件之前,需要针对一些特定的章节删除空行段落,这是jinja2模板带来的结果,只能后续删除
def del_paragragh(para):
"""
delete paragragh with paragraph parent
:param para:
:return:
"""
# https://github.com/python-openxml/python-docx/issues/33
p = para._element
p.getparent().remove(p)
para._p = para._element = None模板渲染
使用python-docx-template和jinja2可以很方便地基于某一些格式化的文档模板生成特定格式要求的word文档,这一块主要来自 https://github.com/elapouya/python-docx-template/tree/master/tests,我在里面找到符合我需求的示例代码。
生成子文档Subdoc
def mk_subdoc(templateObj, tabs: "list"):
"""
生成包含子表的子文档
:param templateObj:
:param tabs: docx对象列表,包含Table和Paragraph,按顺序加入子文档
:return:
"""
sdoc: Document = templateObj.new_subdoc()
p = sdoc.add_paragraph()
p.paragraph_format.first_line_indent = 266700 # 中方段落前空两字
for i in tabs:
if isinstance(i, str):
if p.text != "":
p = sdoc.add_paragraph()
p.paragraph_format.first_line_indent = 266700
p.text = i
elif isinstance(i, Paragraph):
if p.text != "":
p = sdoc.add_paragraph()
p.paragraph_format.first_line_indent = 266700
p.text = i.text
p.style = i.style
elif isinstance(i, Table):
sbtab = deepcopy(i) # 表格复制一下就可以了
p._p.addnext(sbtab._element)
# 删除空行
paragraphs = sdoc.paragraphs
for para in paragraphs:
if para.text.strip() == "":
del_paragragh(para)
return sdoc表格与段落模板
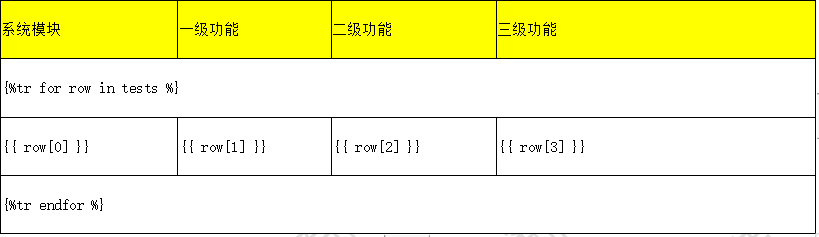
表格模板,主要是{%tr %}、{%tc %},tr就是row方向,tc就是column方向
子文档模板实现段落
当有一个python ['abc', 'efg', ……]列表,可以使用{% for %}迭代生成每一个段落,但如果list里面包含一个Table表格,这个方式就渲染失败,表格没了,这里需要使用{%p %},但python-docx-template又不支持混用。好在官方的test测试案例里面就有子文档的案例,把这个列表直接制作成Subdoc就可以解决此问题
isc_desc = ','.join(set(sum(map(lambda x: x["isc"], funcdesc_list), [])))
table_subdoc_dict = {}
for k, v in table_dict.items():
table_subdoc_dict[k] = mk_subdoc(docTemplate, v)
# 模板中使用,就可以完好地渲染此列表段落以及相应的位置表格
{{p <var> }}数据持久化
python的pickle模块无法dump出python-docx的类型,只能把文本读取出来之后,再dump到数据文件。