4月19日,Meta发布了开源llama3大模型。这是AI界的又一大善举,不少AI创业公司又迎来了重大突破。
这次发布的llama3有2个版本,8B和70B。8B的版本,在测评中,打败了前不久刚发布的Gemma7B版本,而70B版本则打败了Gemini Pro1.5,和Claude3。

llama的400B版本还在训练中,估计发布后要挑战老大哥GPT-4了。现在压力给到OpenAI和Google了。
8B的版本,可以在普通显卡上运行,我测试的量化版本占用显存不到10GB。
今天我就手把手的带大家用最简单的方案在本地部署Llama3-7B。只需要下载安装2个软件就可以运行,都是开箱即用。
一、安装Ollama
Ollama是专门为本地化运行大模型设计的软件,可以运行大多数开源大模型,如llama,gemma,qwen等
首先去官网下载Ollama软件:https://ollama.com/
Ollama已经有Windows版本了,可以选择自己的系统版本下载,下载成功后运行安装即可。
二、配置Ollama,下载模型
配置Ollama
Ollama有两个配置可以选择配置。
- OLLAMA_MODELS OLLAMA模型的下载路径。
- OLLAMA_HOST OLLAMA模型以服务方式运行的时候,即提供API,默认是只能被localhost访问的,设置这个为0.0.0.0,可以被网络访问。
Linux的设置方法:
vim ~/.bashrc
export OLLAMA_HOST=0.0.0.0
export OLLAMA_MODELS=~/ollama_models保存之后,重新登陆会话即可生效
Window的设置方法:
桌面我的电脑右键->属性->高级系统设置->环境变量->系统变量->新建
添加上面二个配置和对应的值。例如:
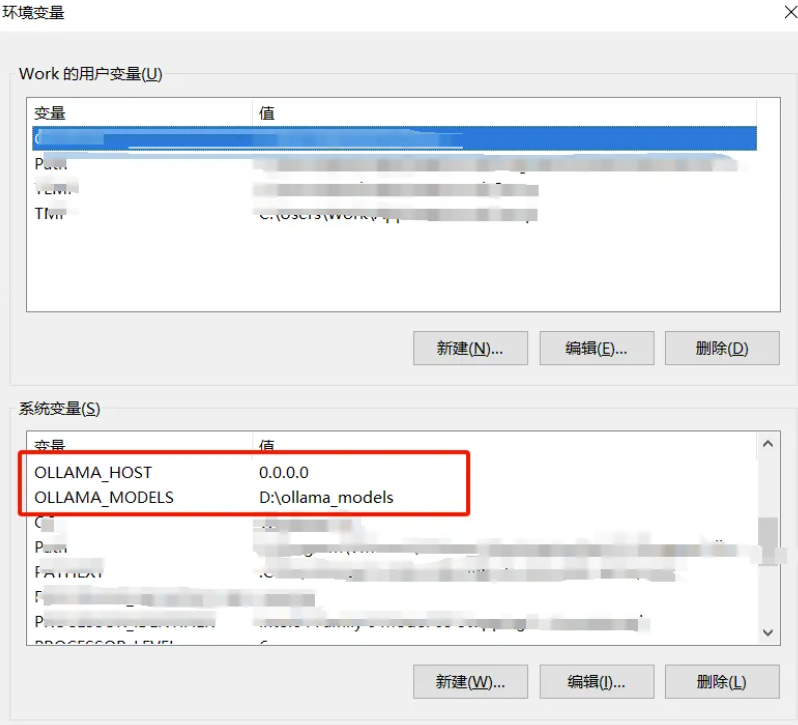
保存后,启动新的CMD命令行就生效了。
接下来所有的命令都在Linux操作系统下操作
Linux的安装方法
# curl -fsSL https://ollama.com/install.sh | sh
# vi /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
#配置远程访问
Environment="OLLAMA_HOST=0.0.0.0"
#配置跨域请求
Environment="OLLAMA_ORIGINS=*"
#配置OLLAMA的模型存放路径,防止内存不足,一般的默认路径是/usr/share/ollama/.ollama/models/
Environment="OLLAMA_MODELS=/home/ollama/.ollama/models"
[Install]
WantedBy=default.target
##修改完后执行
sudo systemctl daemon-reload
sudo systemctl enable ollama
下载模型
访问https://ollama.com/library/llama3/tags,选择所想要下载的模型版本
这里选择llama3:8b模型,这个模型大概4.5G,视网络宽带的情况下载的时长不同,耐心选候。70B模型大概需要60G的内存以及显存。
ollama pull llama3:8b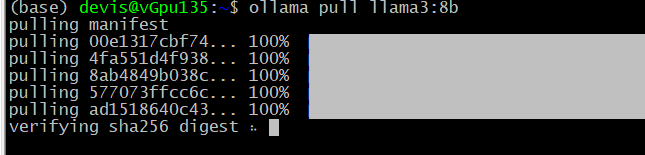
列举模型
ollama list
运行模型
ollama run llama3:8b
愉快的聊天
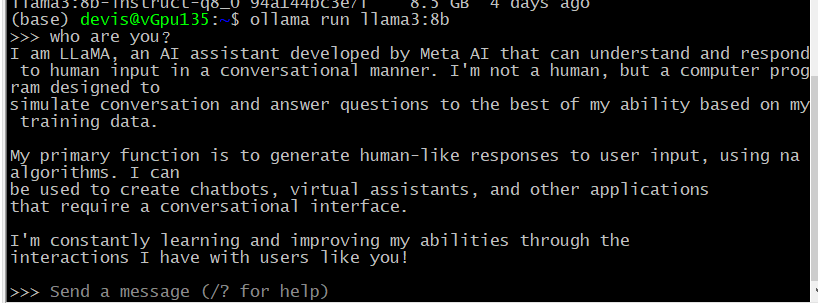
退出命令是/bye
三、客户端
ollama外网访问
ollama可以使用http_rpc方式连接,ollama在后台11434监听网络请求,默认是在127.0.0.1,当需要外网服务时,需要修改配置绑定到0.0.0.0。
修改方法,systemctl edit ollama.service,打开配置,修改里面的环境变量
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
修改完毕之后,重载并重启
systemctl daemon-reload
systemctl restart ollamahttp调用示例
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "Why is the sky blue?",
"options": {
"num_ctx": 4096
}
}'安装Chatbox客户端
在命令行中使用可能有诸多不便,我们可以再安装一个客户端来使用。客户端软件有非常多。这里我介绍一个安装使用最简单的。
首先在chatbox官网下载软件 https://chatboxai.app/zh
下载完成后运行安装,按提示步骤安装即可。
安装完成后,打开软件,在设置中配置以下信息:
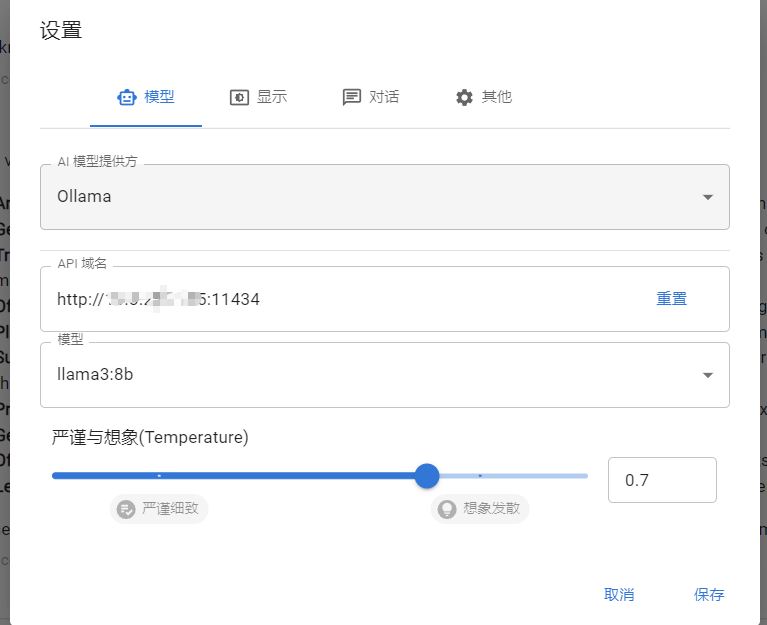
AI模型提供方:Ollama
API域名:http://localhost:11434 如果是本机安装的填这个localhost就可以,11434是Ollama服务运行的端口号。
模型下拉里选择llama3:8b。然后保存即可。
接下来就可以愉快地和llama3玩耍啦。
LLAMA3体验
llama3整体的推理,逻辑能力都不错。美中不足的是对中文不太友好。但是比llama2已经好了很多。
LLAMA3的训练语料大概只有5%是非英文内容。
它能够看懂中文,但大部份的回答都会用英文回答,除非你要求它用中文回答。
但是当用中文回答时,逻辑明显就不如英文。例如,我问一个鸡兔同笼的问题:
一群兔子和鸡,共有20个头,50只脚。有几只兔子,几只鸡?
英文的回答是正确的
而中文的回答就是错误的
此外我们也发现,现在同样参数量级的大模型,一代比一代更强了。这最主要的原因是数据。llama3用了15T的token训练,数据量是llama2的7倍,是gemma的2倍。除了数据,模型的架构、代码工程也都会逐渐改进提升。未来模型的能力还有很大的提升空间。
最牛逼的是Meta为了训练llama3,堆了近5万张H100卡。一张H100卡大概值一辆su7,关键国内还买不到,只能靠黄牛背回来。
希望我们早日突破科技封锁吧。